Extracting tables from PDF
The PDF format has no representation of a table structure, which makes it difficult to extract tables. In this post we show how to extract table data with a few simple steps.
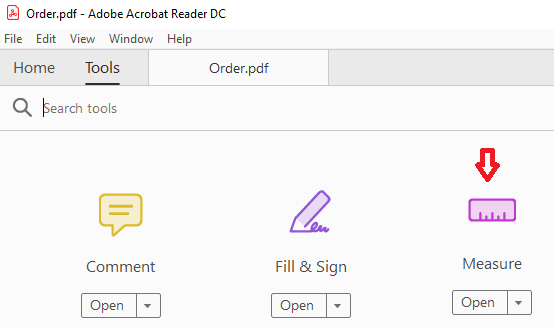
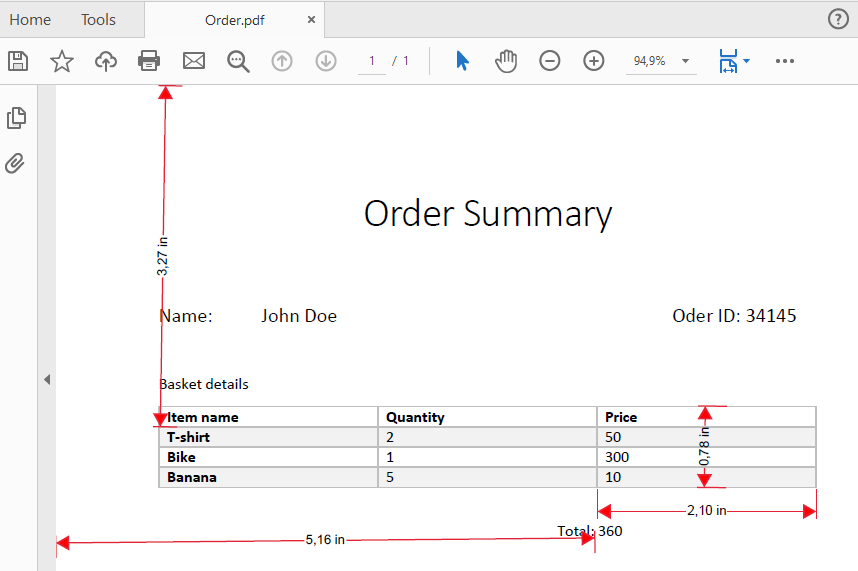
The VBO used for table extraction is Utility – PDF that you can find in our store. We use the Get text From Area action which needs coordinates of the desired table. To get the coordinates we can use the built-in Measure feature from the Acrobat Reader.
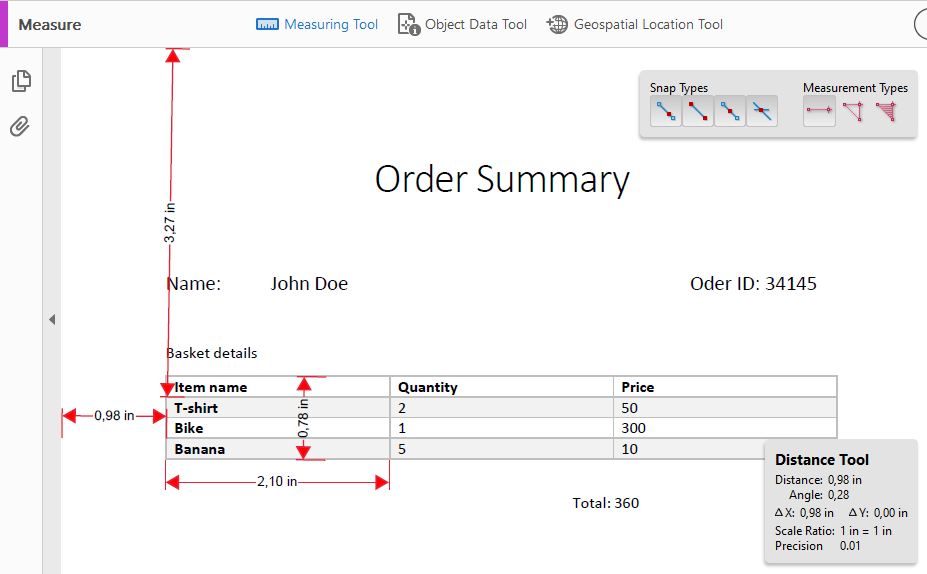
Now we have to measure the section we want to extract the data from. In this case we start with the Item Name column.
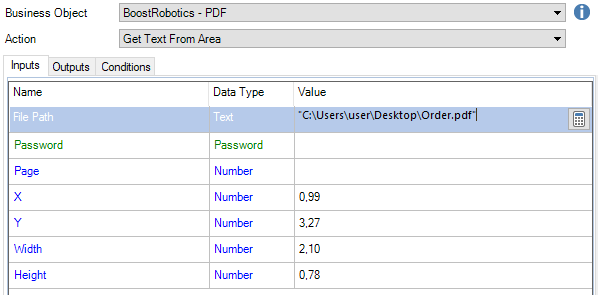
Now we can pass the parameters to the Get Text From Area action.
As the result we get the Text.
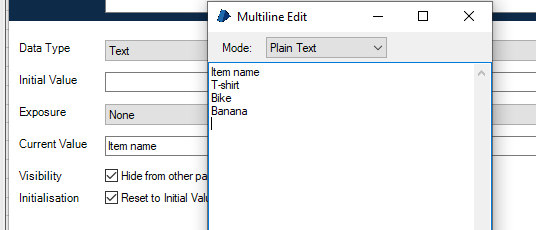
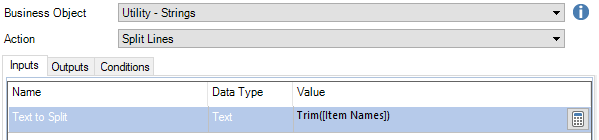
To change the Text to collection we can use Split Lines action from Utility – Strings.
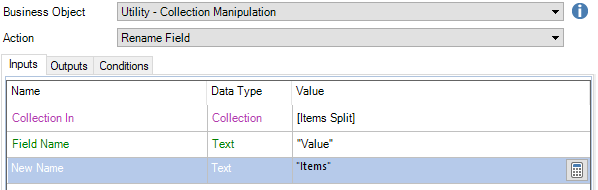
Also we can change the column name using Rename Filed action from Utility – Collection Manipulation.
And that’s it! We have the first column in the collection. Let’s extract another one, e.g. Prices. All steps are the same except the X coordinate which has to point to the last column.
Once again we execute the actions. Now we have two collections – one for each column. To merge them into the final table we use Merge Collection action from Utility – Collection Manipulation.
The sample process view below:
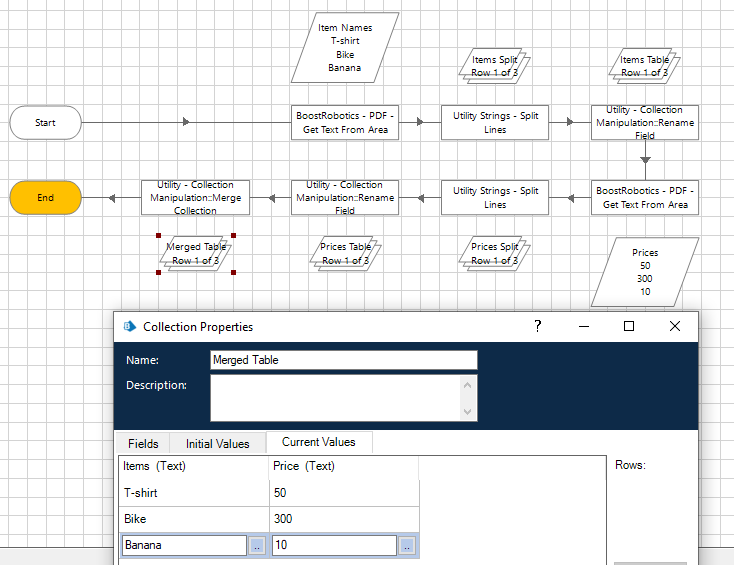
Feel free to download the example process code. It requires some VBOs to work properly:
- Utility – PDF (trial version for free)
- Utility – Collection Manipulation (standard Blue Prism VBO)
- Utility – Strings (standard Blue Prism VBO)
Recent Comments